How Do Generative Pre-Trained Transformers (GPTs) Work Under the Hood?
I watched a YouTube video on how large language modles work under the hood. Specifically, the YouTube channel 3Blue1Brown visually explained what happens inside a large language model transformer.
The following post contains my notes! Hope you enjoy.
Lets Breakdown The Words “Generative Pre-trained Transformer”
Generative
Generative refers to bots that can generate new text
Pre-trained
Refers to how the model learned from a massive amount of data. The prefix “pre” also implies that the model can be further trained on new data.
Transformer
A transformer refers to a specific type of machine learning model called a neural network. This is the core invention that is powering the current AI hype.
It’s worth nothing that you can build many types of models using transformers such as
- voice to text - take in audio and produce a transcript
- text to voice - produce synthetic speech from text
- text to image - produce an image from text description
- translate text to another language - first transformer created by google
The rest of this post will focus on a transformer that takes a text prompt and produces a prediction for what should come next.
How Does Data Flow Through a Transformer?
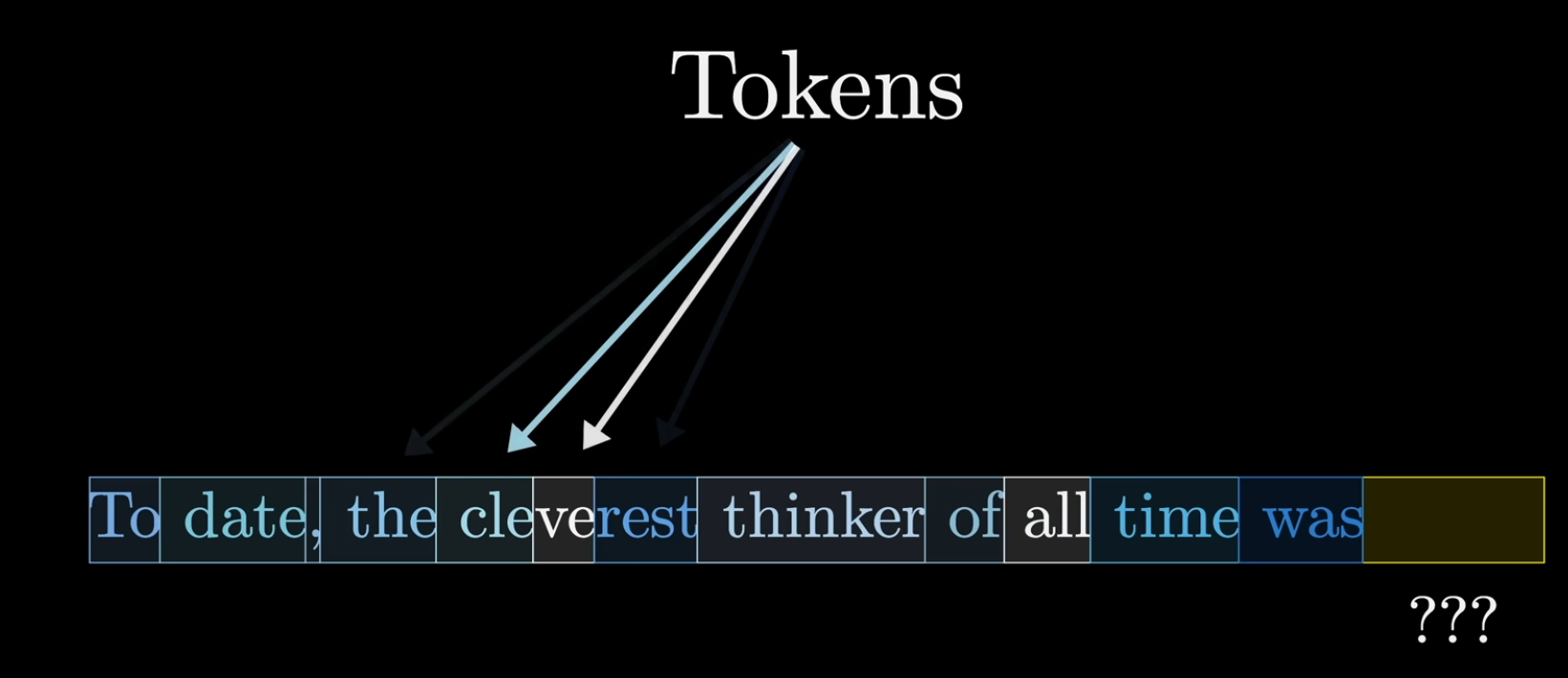
The Input is Broken Up Into Pieces called Tokens
Tokens aren’t always whole words. They can be pieces of words or the word themselves.
Each Token is Associated with a Vector
The vector is meant to encode meaning for each piece.
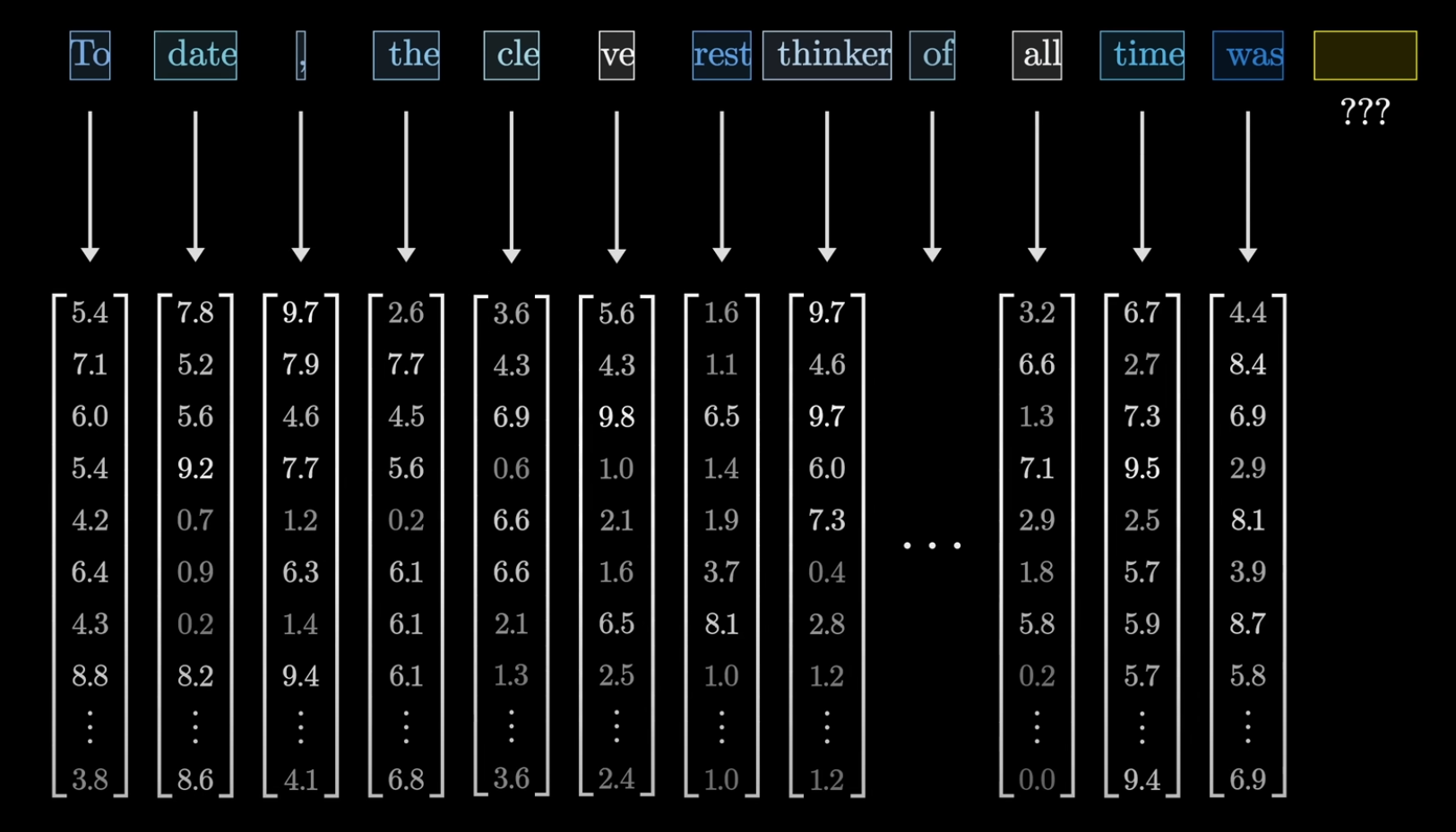
Words with similar meanings tend to land on vectors that are close to each other.
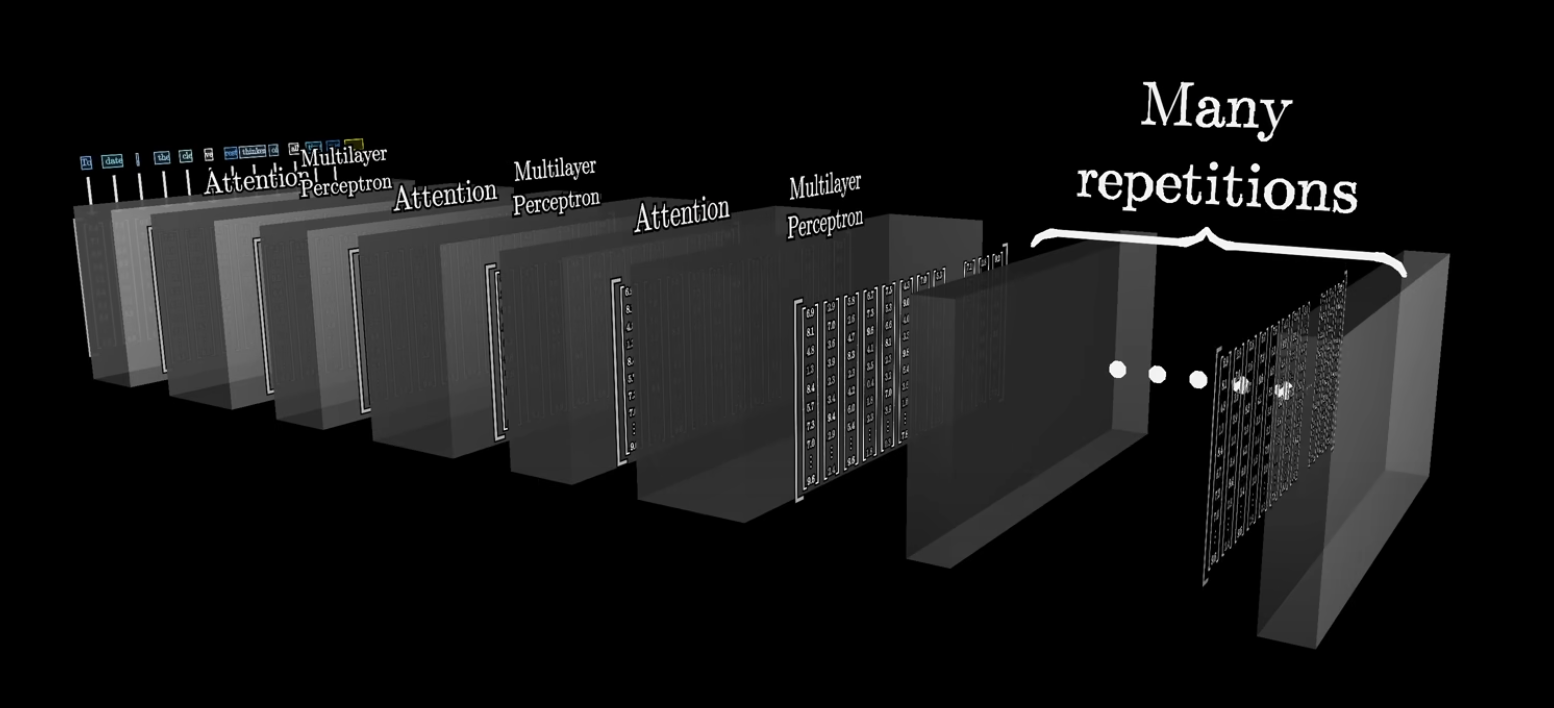
The Sequence of Vectors is Passed Through an Attention Block
The attention block allows vectors to communicate with each other and update their values. That is, the attention block is responsible for figuring out which words in the context are relevant for updating the meaning of other words and how they should be updated.
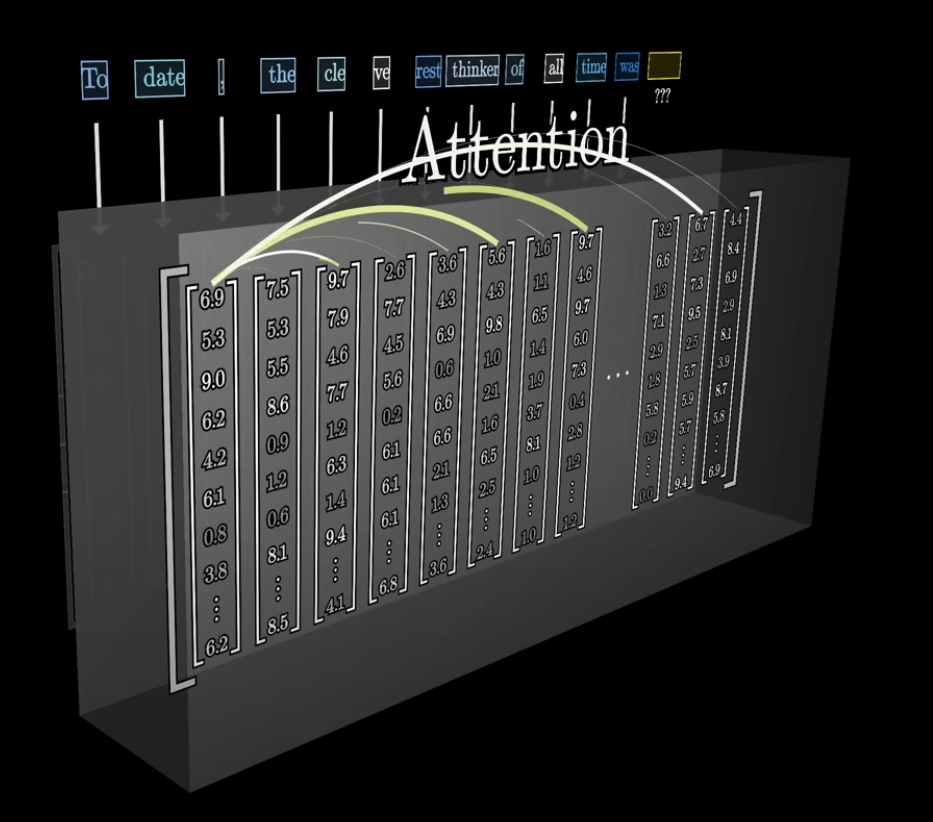
For example, the meaning of the word model will be different in the phrase A machine learning model vs the phrase A fashion model .
The Vectors Pass through a Multilayer Perceptron
The vectors go through the same operations in parallel.
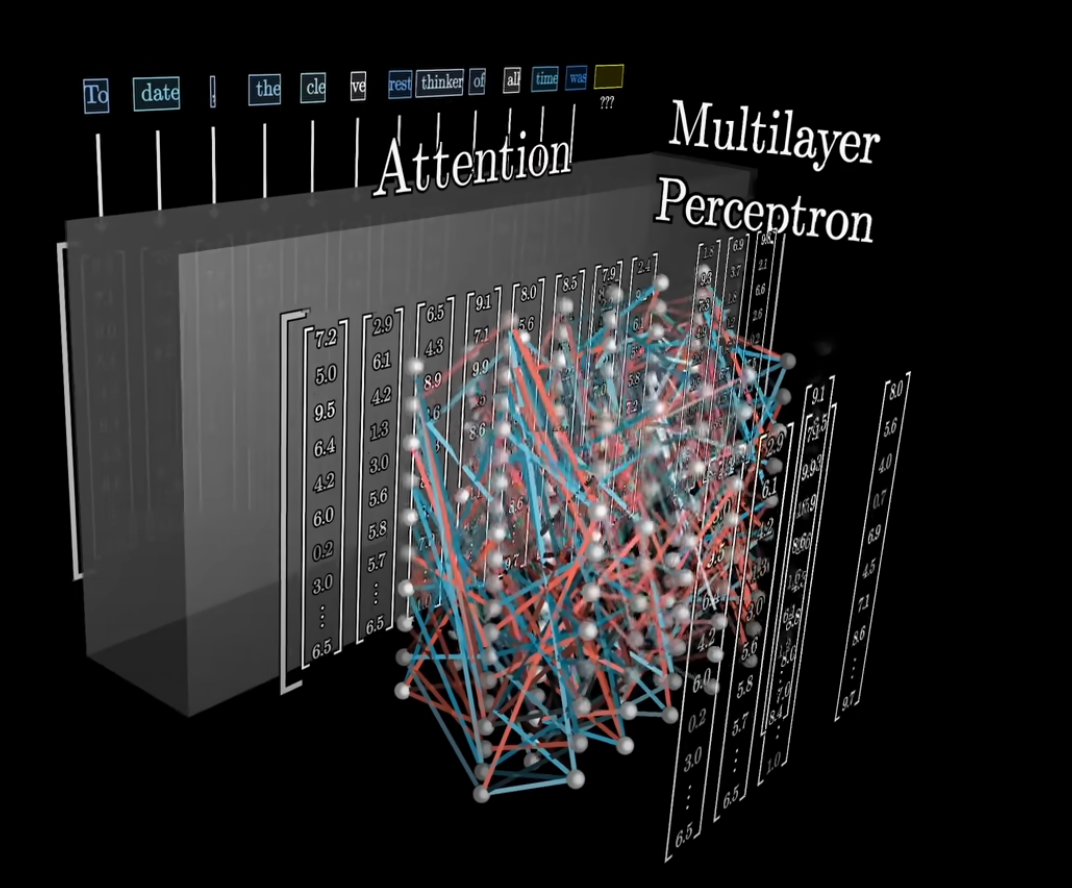
This step is like asking a long list of questions for each vector and then updating them based on the answers to the questions.
The Essential Meaning of the Input Should be Baked into the Last Vector
The vectors will pass through many attention and multilayer perceptron blocks.
Eventually, an operation is performed on the last vector which should provide a probability distribution over all possible tokens.
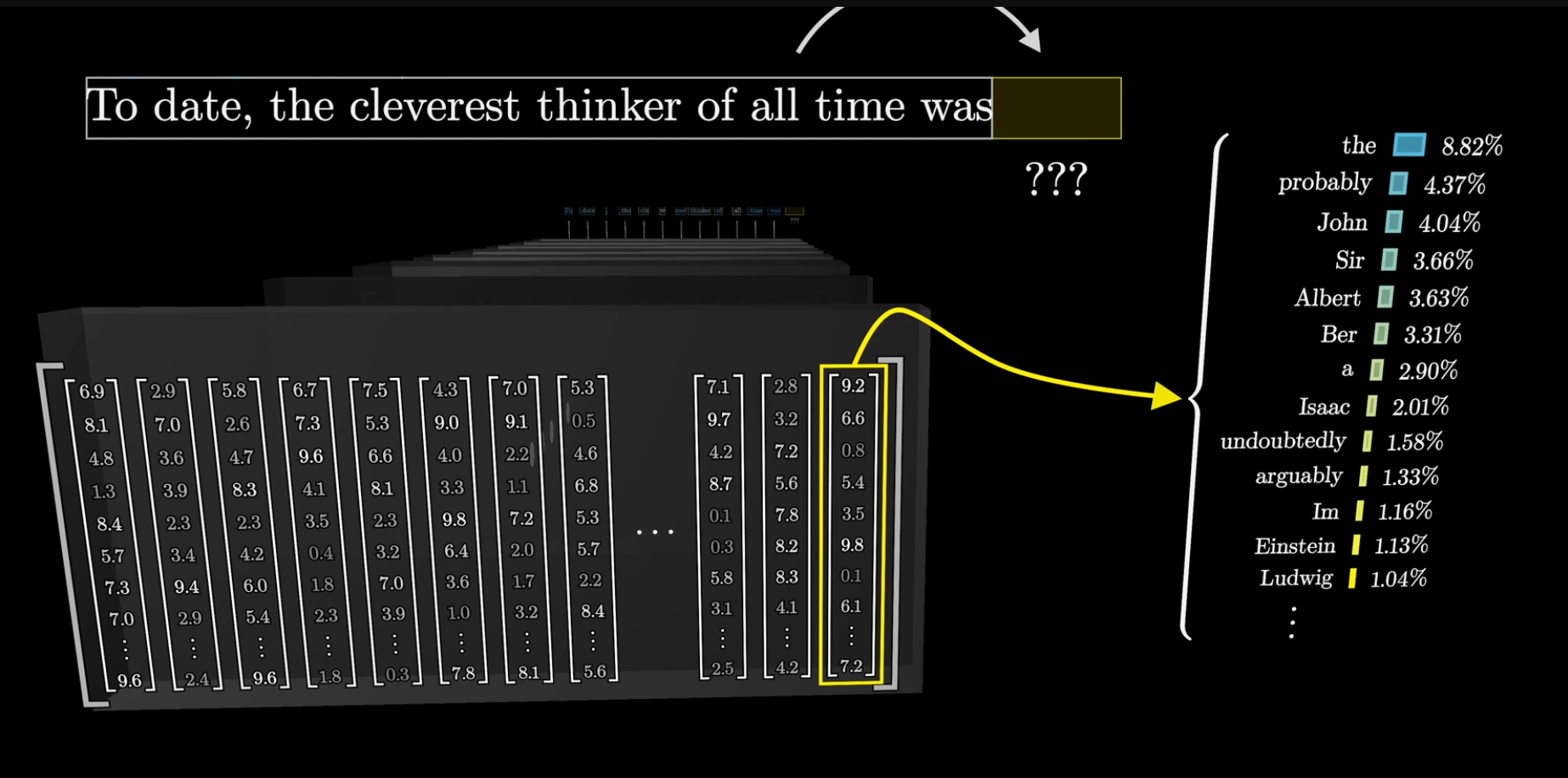
Then you repeat over and over slightly smiling 😁.
The Premise of Deep Learning
Deep Learning is one approach to Machine Learning. Machine Learning can be described as any model where you are using data (input) to somehow determine how a model behaves.
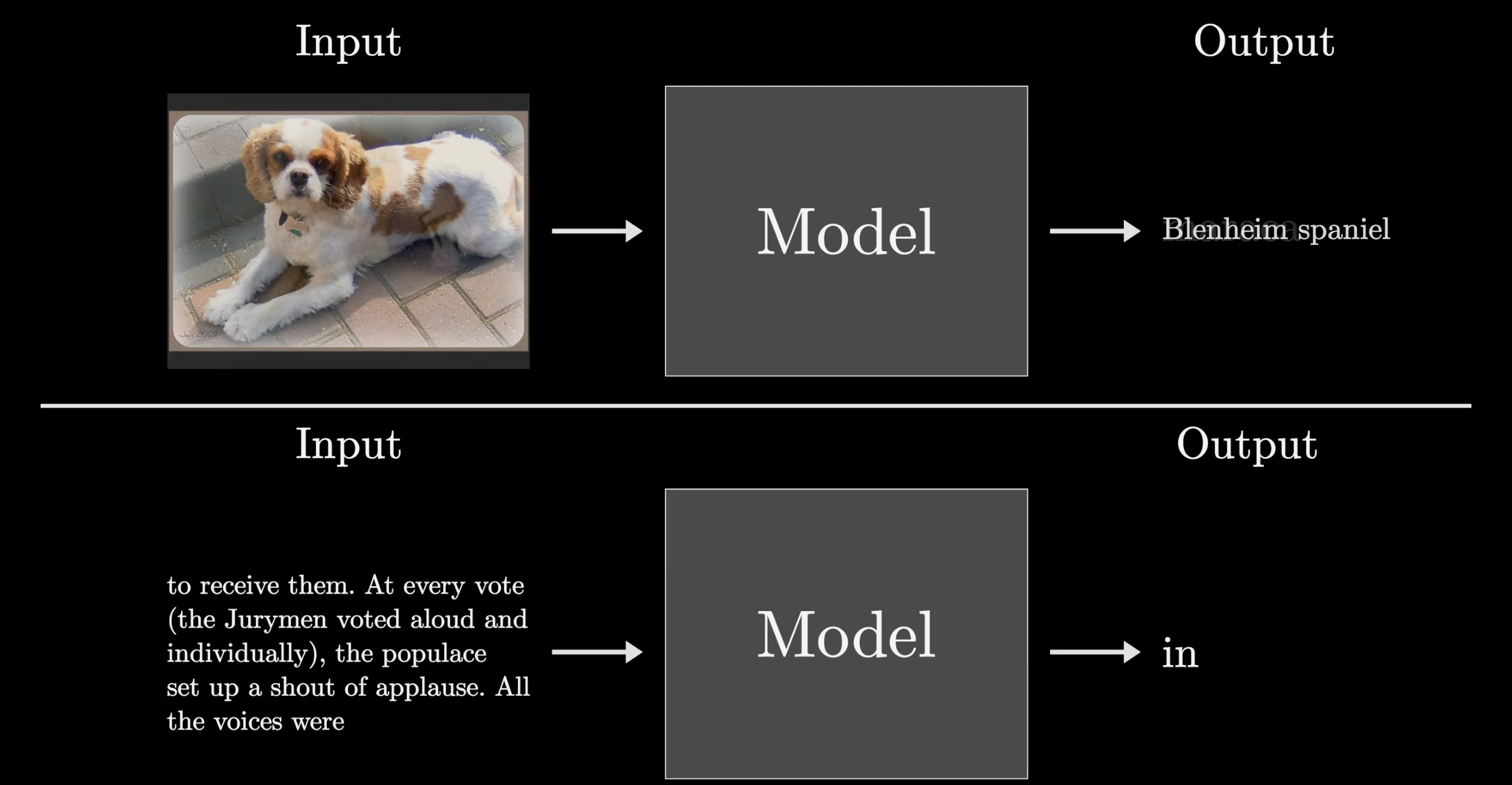
Deep learning models all use the same training model called Backpropagation.