Mastering Chaos - A Netflix Guide to Microservices
Here are my notes from watching a former Netflix director of engineering discuss Microservices.
Speaker

What Microservices are not
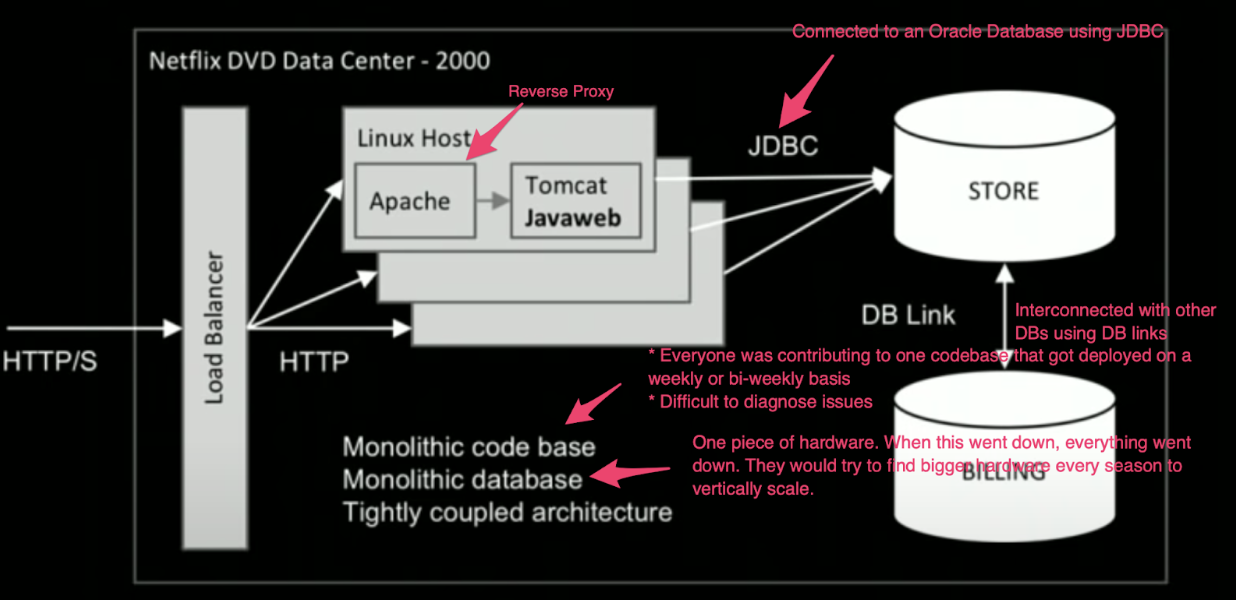
What is a Microservice?
… the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
Martin Fowler
Microservice architectures are complex and organic
- Health depends on discipline and chaos
- The Microservice definition has evolved over time
Separation of Concerns
- Modularity - ability to encapsulate data structures
- Encapsulation
Scalability
- Horizontal scaling
- Workload partitioning
Virtualization & Elasticity
- Automated operations
- On demand provisioning
Organ Systems
- Each organ has a purpose
- Organs form systems
- Systems form an organism
Microservices are an abstraction
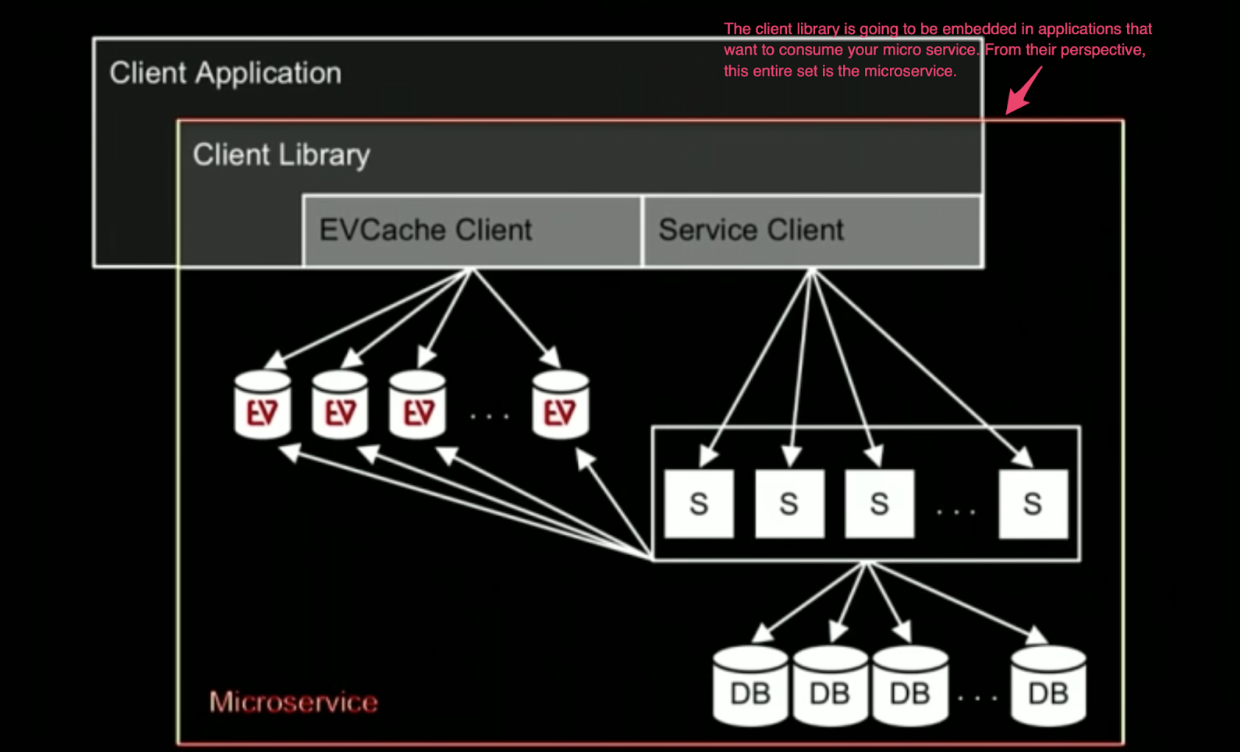
Challenges & Solutions
Dependency
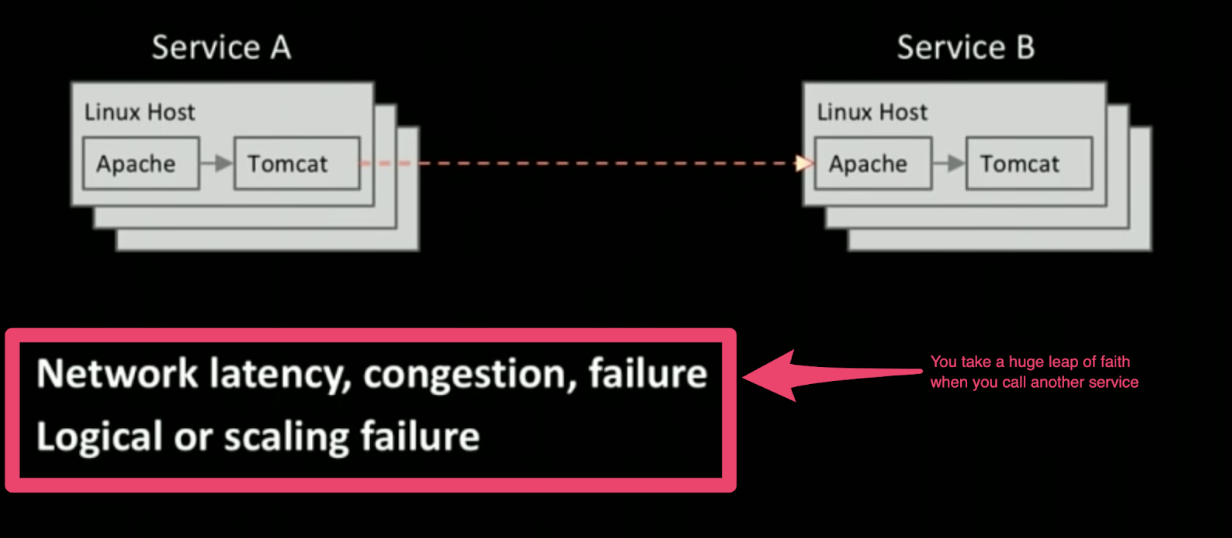
Intra-service Requests
An intra-service request is the call from microservice A to microservice B.
Hystrix
Structured way for handling timeouts and retries Has a concept of fallback which returns a static response or something if a service is down Circuit breaking
Fault Injection Testing (FIT)
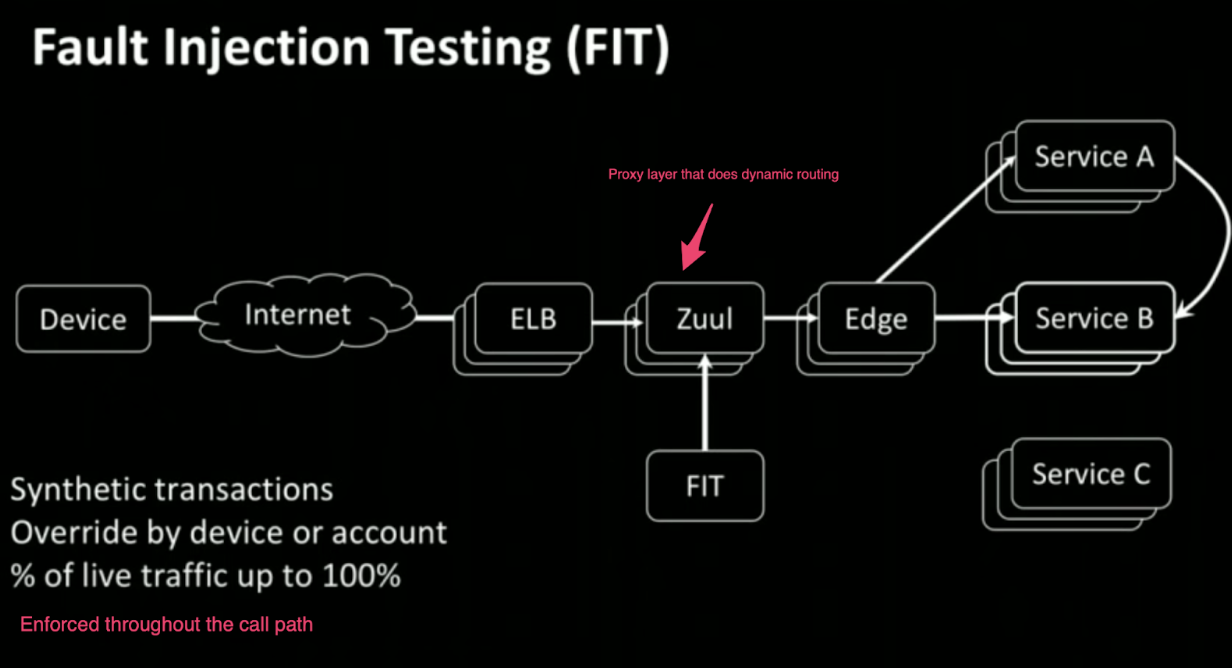
Critical Microservices
Define microservices that are necessary to have basic functionality to work Netflix identified a group of microservices and created FIT recipes to make sure the service/application functions as expected
Client libraries
Netflix had two camps when it came to client libraries bare bones rest calls; don’t create a client library Build client libraries that have common business logic and access patterns so teams didn’t recreate patterns
Return of the Monolith
This was a slippery slope because Netflix’s API Gateway had to run a lot of code (clients) that they didn’t write. This felt like a monolith because lots of code (client libraries) were running in the same code base.
Client libraries will do things you don’t expect
Heap consumption Logical defects Transitive dependencies
Data Persistence
Josh claims that Netflix got persistence right from the beginning. They got it right by thinking of the right constructs and thinking about CAP Theorem
CAP Theorem
In the presence of a network partition, you must choose two of the following three guidelines
- Consistency - Every read receives the most recent write or an error
- Availability - Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition Tolerance - The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
Netflix Embraced Eventual Consistency
Eventual Consistency
After a call to an S3 API function such as PUT that stores or modifies data, there’s a small time window where the data has been accepted and durably stored, but not yet visible to all GET or List requests https://aws.amazon.com/blogs/aws/amazon-s3-update-strong-read-after-write-consistency/
Local Quorum
I need this many nodes to respond back and say they have committed the change before I’m going to assume that it has been written out.
Infrastructure
Netflix developed a multi-region strategy with three regions such that if any failed, they could push remaining traffic to the surviving regions.
For more information, watch the #NetflixEverywhere Global Architecture presentation by Josh Evans
Scale
Three scenarios to care about
- Stateless service
- Stateful service
- Hybrid service
Stateless Service
A stateless service is
- Not a cache or a database
- Frequently accessed metadata
- No instance affinity - you won’t expect a customer to stick a specific instance
- Loss of a node is a non-event
You need to be able to replicate a service. Netflix uses AWS auto-scaling groups.
Chaos Monkey
Surviving Instance Failure https://netflix.github.io/chaosmonkey/
Stateful Services
A stateful service is
- Databases & caches
- Sometimes custom apps which hold large amounts of data
- Loss of a node is a notable event - it may take hours to replace that node and spin up a new one
Caching
Dedicated Shards - An antipattern
A dedicated shard for a set of customers can be a point of failure for your entire application
EVCache Reads
EVCache is a wrapper over Memcached. It is sharded where multiple copies are written out to multiple nodes.
Netflix uses EVCache with almost every service that needs a cache.
Hybrid Services
Combination of stateful and stateless services.
For ideas on what upstream services should do if a downstream service goes down, watch https://youtu.be/CZ3wIuvmHeM?t=1881. Possible solutions could be Workload partitioning Request-level caching Secure token fallback
Variance
Variance means variety in your architecture.
Operational Drift
Overtime
- Alert thresholds
- Timeouts, retries, fallbacks
- Throughput (RPS)
Unintentional Variance
Across microservices
- Reliability best practices
Polyglot & Containers
- Intended variance
- People want to include new technologies/languages
Change
Conway’s Law
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.
Or
Any piece of software reflects the organization structure that produced it.